Final.激活Knife4j官网的文档搜索功能
1.前言
在很早之前,Knife4j的官网文档就通过docusaurus进行了重构,在网上找了一个自己还算满意的模板,将所有的Knife4j的Markdown文档进行了重新梳理改造。
但是后面有一段时间,也是自己懒的原因,文档中的搜索功能一直不可用。每天都会收到搜索的统计结果报告,提示的都是在搜索的请求中,未匹配结果的概率始终100%
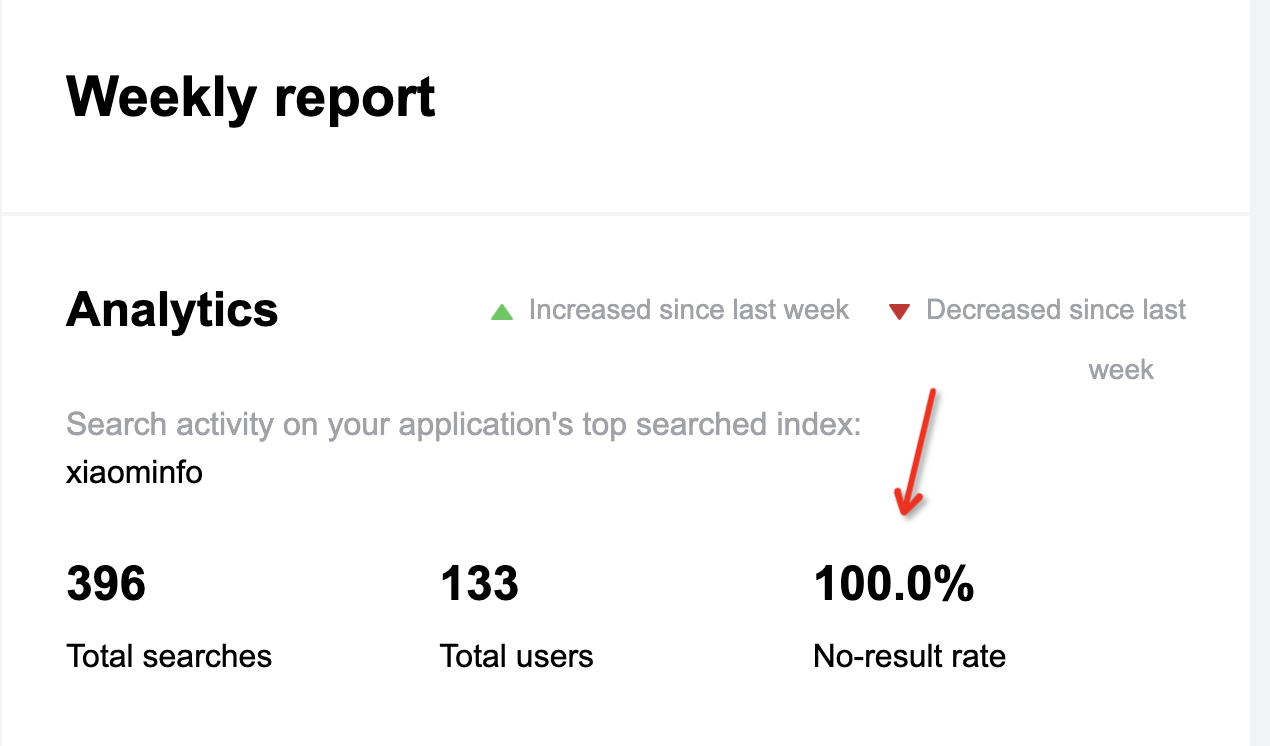
看的也是相当难受,这两天终于投入了时间,决心解决这个问题。
2.Algolia
Knife4j的官网搜索主要集成了Algolia来提供搜索服务,因为docusaurus纯天然支持Algolia来集成文档搜索服务,如果用过Algolia的服务的朋友可能知道,如果你的网站文档是开源项目,那么是可以提交申请来获取免费服务的,主要条件:
- 必须是文档网站的 所有者,网站必须是 公开的。
- 网站内容必须是 开源项目的技术文档 或 技术博客。
- 网站申请服务时必须有 完整稳定的设计和内容,即确认网站做好生产准备。
2.1 自动爬虫索引数据
申请链接地址:https://docsearch.algolia.com/apply/
但你提交了申请,并且官方社区审核通过后,你会收到邮件,按邮件的内容进行回复就可以了。
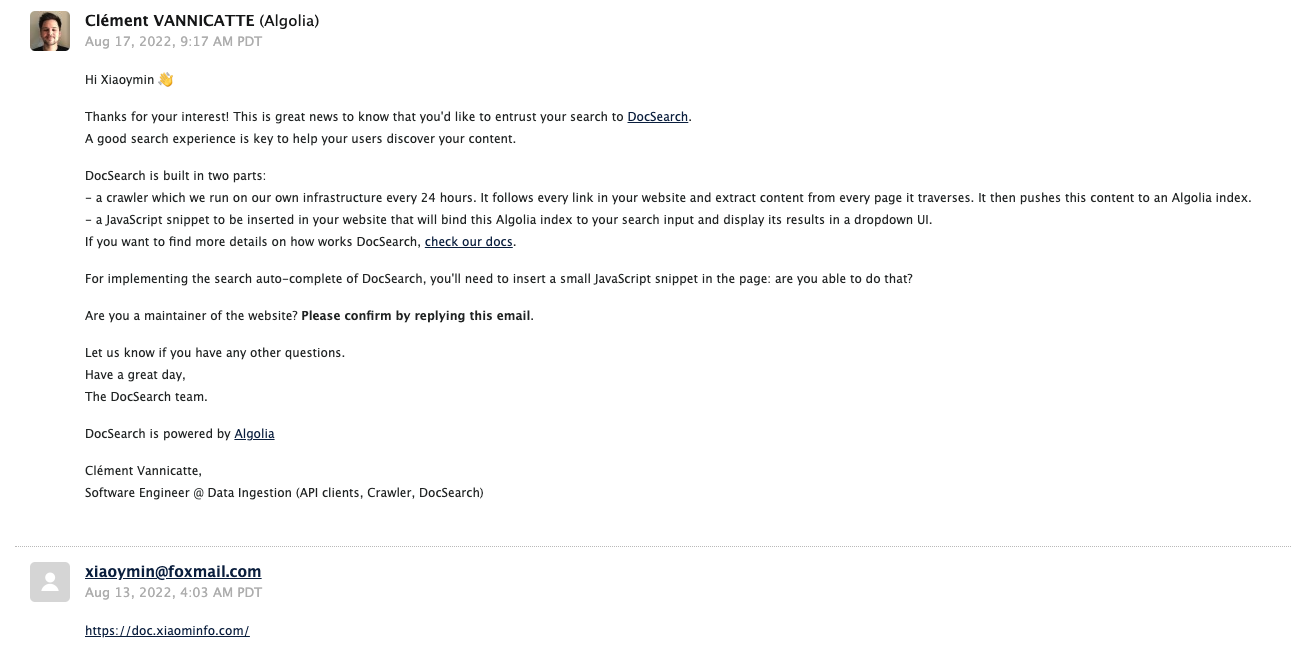
但我们把所有的工作流程准备就绪后,我们就可以前往Algolia管理自己的后台数据了,主要步骤:
步骤一、登录到Algolia里面的控制台
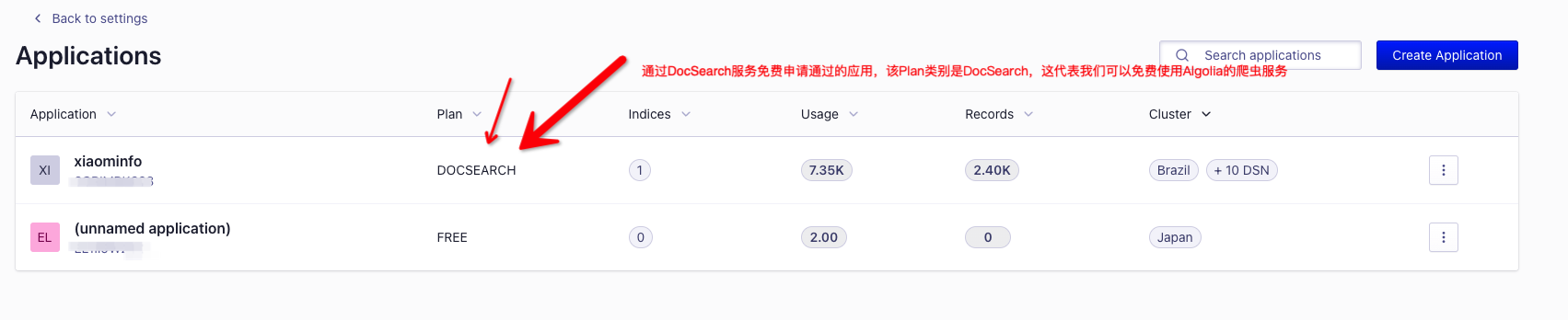
步骤二、可以查看当前自己的Application应用的Plan类别,如下:
Plan类别是DOCSEARCH类型的应用,代表我们可以免费使用Algolia的爬虫服务,会自动爬取我们的网站文档进行索引
如果是FREE类别,则没有这种服务,你也登录不了Algolia的爬虫后台
步骤三、点击Search后,即可查看该文档页面的Index数据集
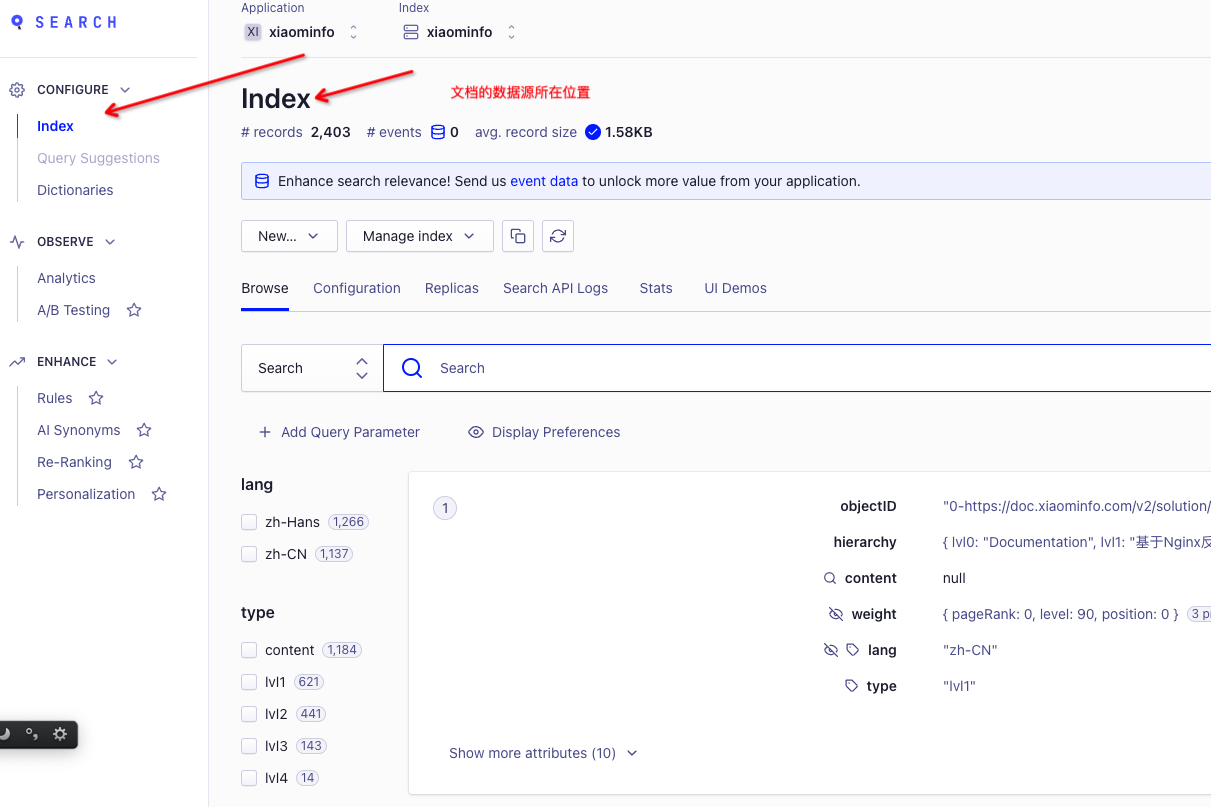
这里Index有数据是核心和关键,如果你的搜索服务不可用,首先要确认一下该Index中是否有数据,或者你文档中配置的搜索配置信息是否正确。
第三,确认自己的爬虫后台是否有问题,登录到Algolia的爬虫后台,地址:https://crawler.algolia.com/admin/crawlers
确认右侧Indices中有数据才正常
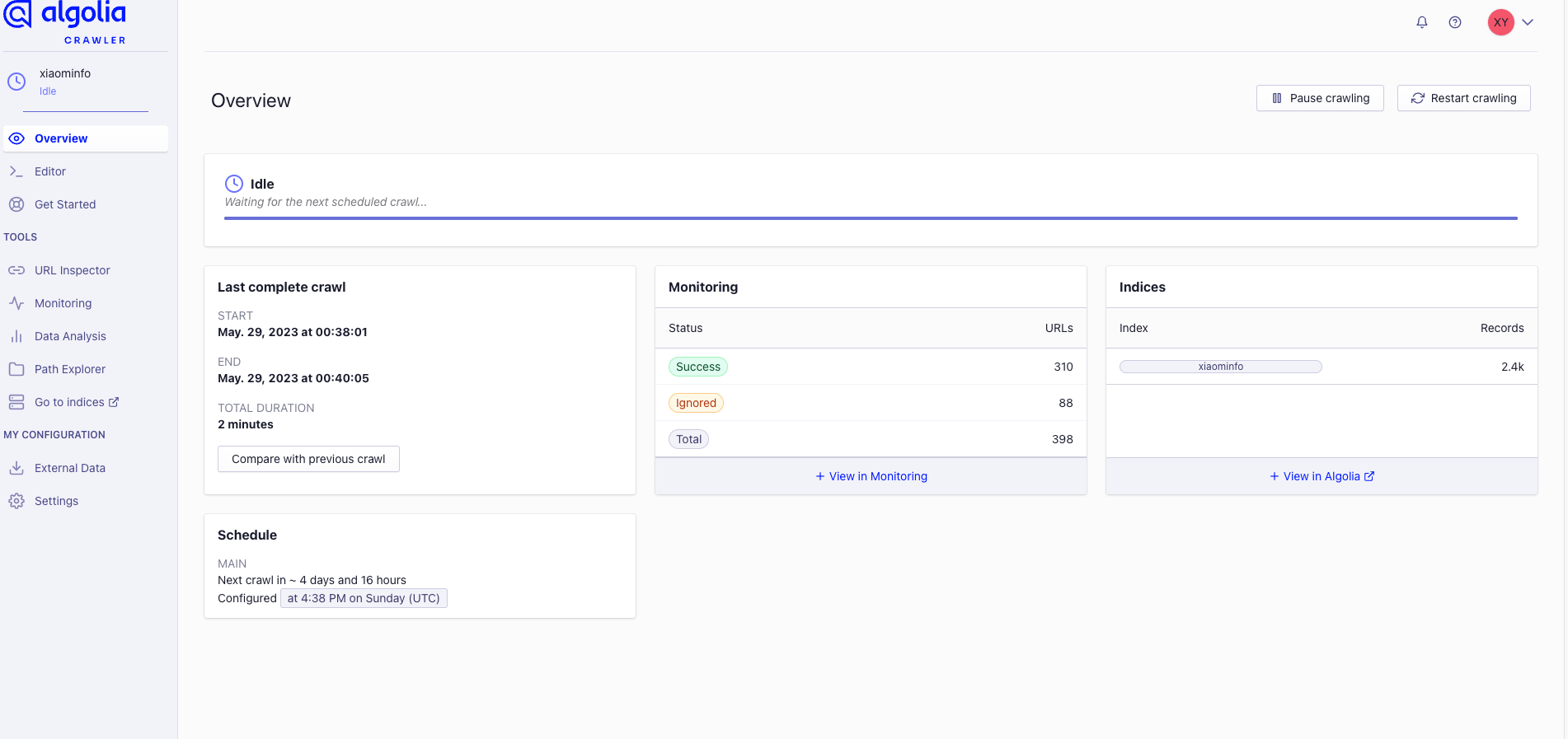
因为Knife4j的DocSearch申请的已经有一段时间了,只是在搜索的时候一直无法展示结果(这让我也一直很困惑),所以,我们就可以使用docusaurus提供的官方algolia插件进行集成搜索
2.2 自己通过Algolia的爬虫送数据
Algolia除了通过DocSearch的方式进行申请,免费使用Algolia的爬虫服务,如果有一些特殊原因,或者最终没有被Algolia的官方社区审核通过,那么也是可以使用Algolia的搜索服务的,可以自己注册Algolia的后台,然后创建Application(应用)
创建应用后,就可以通过Algolia提供的爬虫程序(离线工具)自己设置爬虫规则,将爬取的数据送到Algolia控制台。
本文只介绍通过Docker镜像来运行爬虫的工具,其他方式可以参考官方文档:https://docsearch.algolia.com/docs/legacy/run-your-own
docker命令
docker run -it --env-file=.env algolia/docsearch-scraper
然后配置.env环境变量,主要有三个:
APPLICATION_ID:应用APPID,这个可以在Algolia的后台进行创建然后获取得到API_KEY:密钥key,在Algolia的后台,可以创建API_KEY,也可以使用当前应用的AdminKey(ps:因为爬虫程序在你本机使用,没有人知道,所以用admin的key可以一步到位,避免一些权限问题会提示key无效或者无权限等问题的发生)CONFIG: 目标网站的爬虫规则,详细规则参考文档:https://docsearch.algolia.com/docs/legacy/config-file
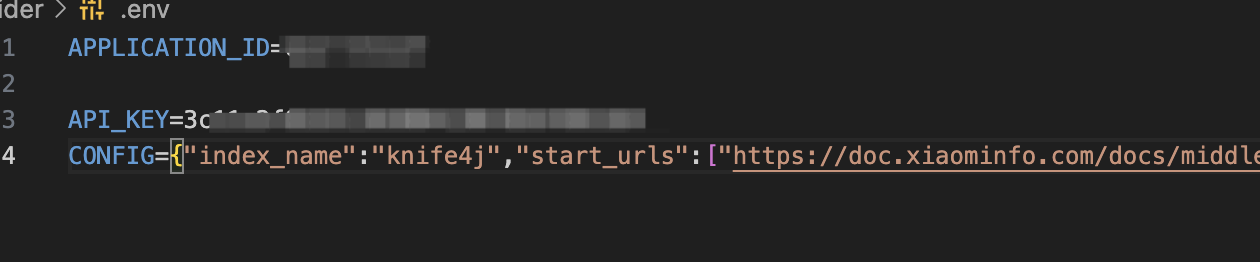
Config示例如下:
{
"index_name": "knife4j",
"start_urls": [
"https://doc.xiaominfo.com/docs/middleware-sources",
"https://doc.xiaominfo.com/docs/oas",
"https://doc.xiaominfo.com/docs/action",
"https://doc.xiaominfo.com/docs/changelog",
"https://doc.xiaominfo.com/docs/faq",
"https://doc.xiaominfo.com/v2/"
],
"selectors": {
"lvl0": ".docMainContainer_gTbr header h1",
"lvl1": ".docMainContainer_gTbr article h1",
"lvl2": ".docMainContainer_gTbr article h2",
"lvl3": ".docMainContainer_gTbr article h3",
"lvl4": ".docMainContainer_gTbr article h4",
"lvl5": ".docMainContainer_gTbr article h5",
"text": ".docMainContainer_gTbr header p,.docMainContainer_gTbr section p,.docMainContainer_gTbr section ol"
}
}
几个重要的参数:
- index_name:索引名称,这个是在algolia后台创建的
- start_urls:目标文档网站的目标页
- selectors:选择器规则,也就是告诉爬虫,你需要爬取的网页,最终通过选择器获取的类容规则,包括id选择器、类选择、标签选择器等等,如果你用过
jQuery,看到这个规则应该会非常熟悉
当然还有更详细的规则,具体的可以参考文档进行配置即可。
最终运行docker命令爬虫效果如下:
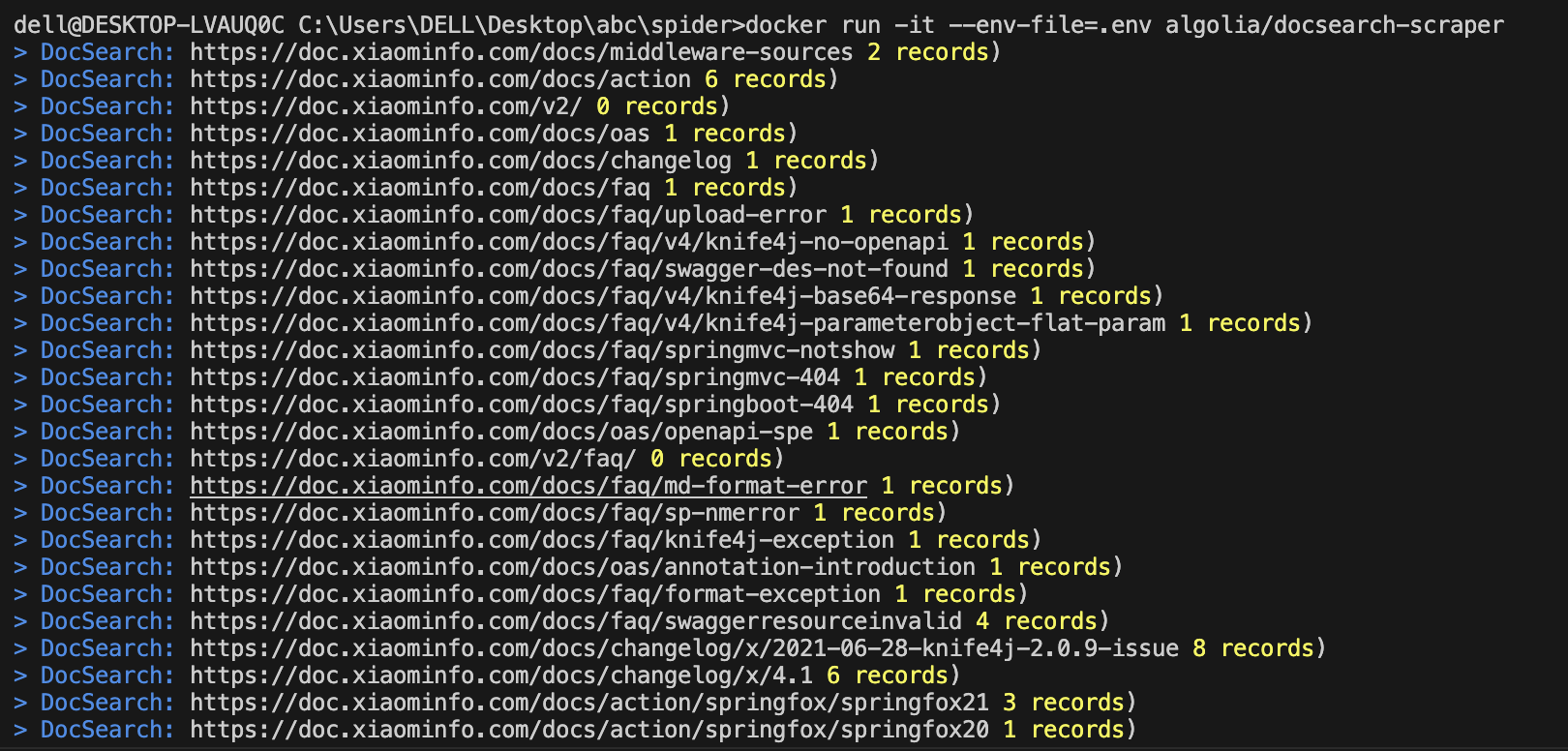
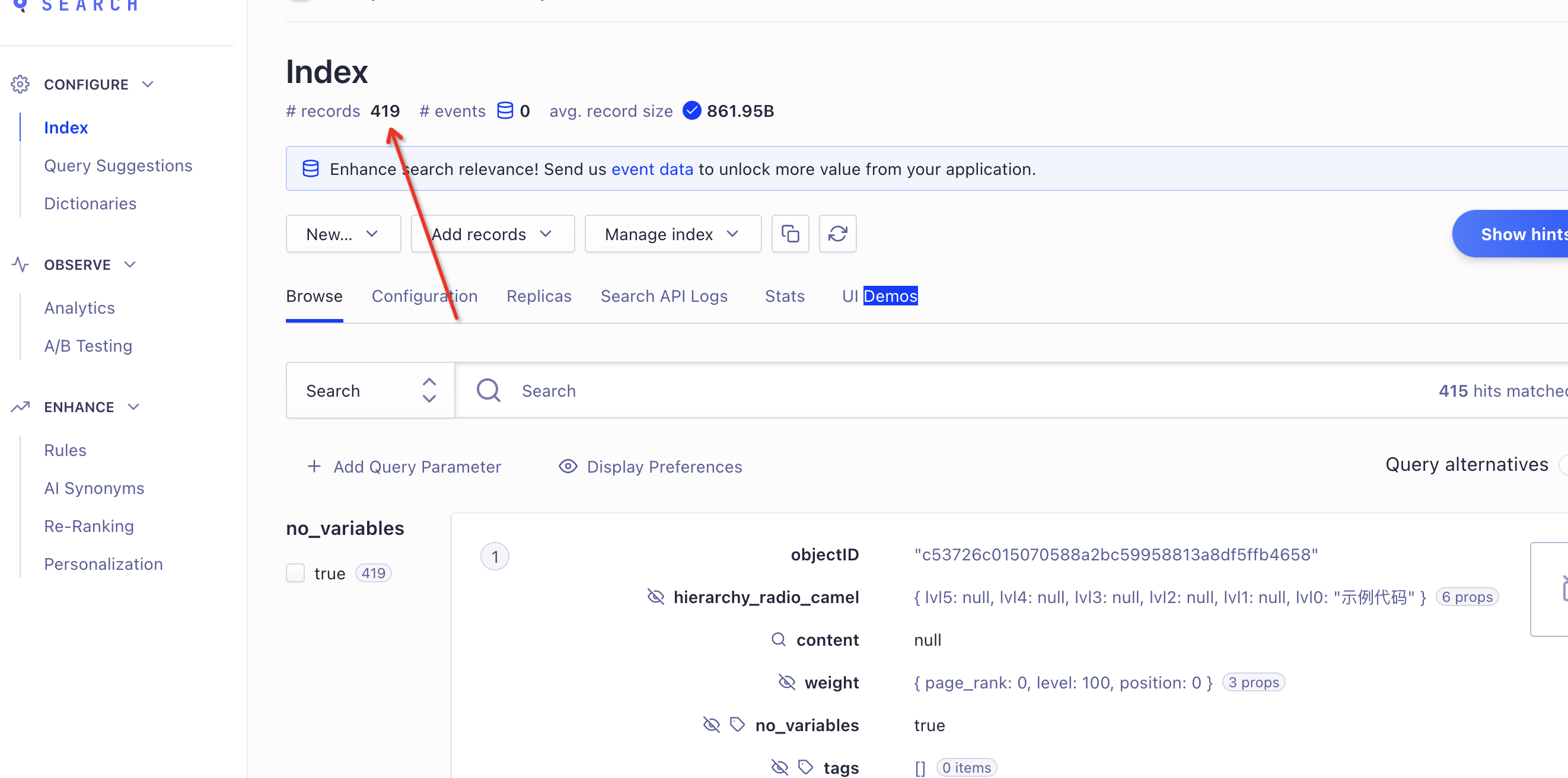
等我们的爬虫在本地运行完成后,我们就可以登录后台查看我们的记录是否成功,现在的records就是最终的文档记录数
3.简单验证Algolia的数据结果&搜索
在上面的章节中我们介绍了怎么在Algolia进行索引数据,主要包括两种方式:
- 官方提交DocSearch申请,通过Algolia提供的爬虫自动爬取我们的公开网站,需要审核
- 自己运行Algolia的爬虫程序,离线将自己的网站索引数据送到Algolia中
这两种方式任何一种你都可以成功索引文档数据,如果在Algolia的控制台能看到数据,那么你可以通过下面一个小demo来验证搜索结果了,废话不多说,直接上html测试代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@docsearch/css@3"/></pre></li>
</head>
<body>
<div id="test"></div>
<script src="https://cdn.jsdelivr.net/npm/@docsearch/js@3"></script>
<script type="text/javascript">
docsearch({
appId:"替换为你自己的appid",
apiKey: "替换为你自己的apikey",
indexName: "替换为你自己的indexName",
container: '#test',
debug: false // Set debug to true if you want to inspect the modal
});
</script>
</body>
</html>
界面效果如下:
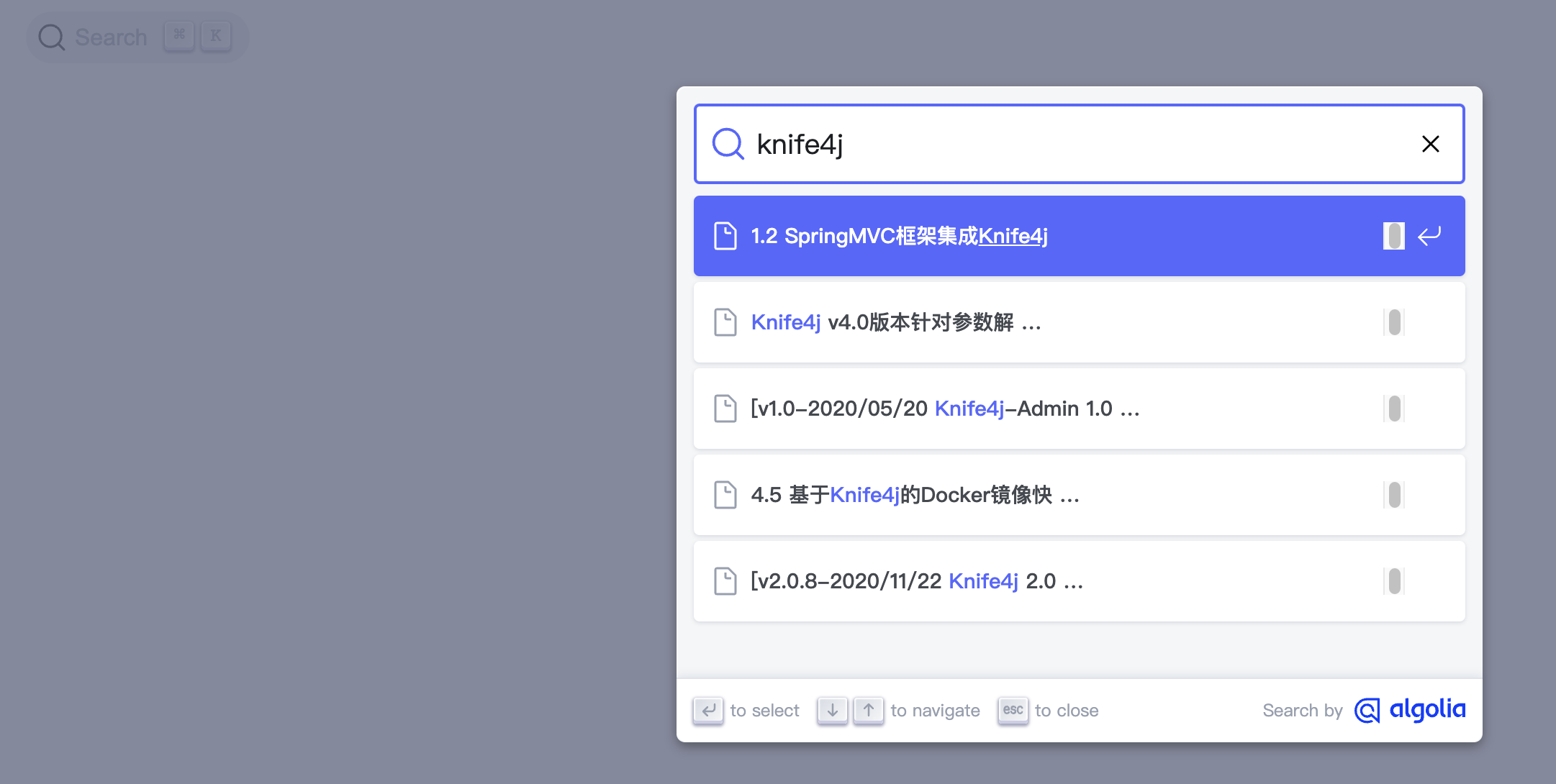
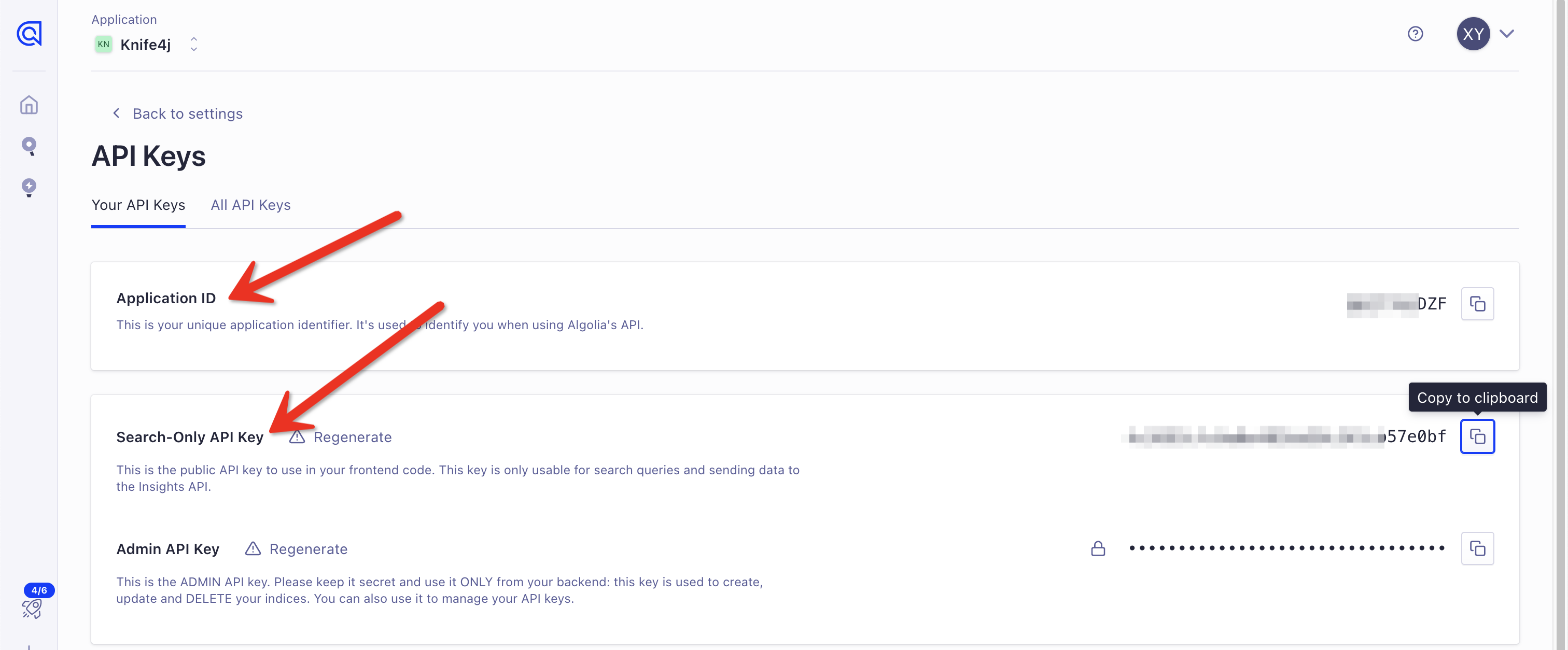
代码中的appid、key需要替换为自己的,可以在Algolia后台获取:
4.Docusaurus集成
前面已经提过,由于docusaurus官方提供了对Algolia的支持,所以万事俱备,只需要配置即可,在docusaurus.config.js配置文件中,直接配置appid、key就可以了
themeConfig:
/** @type {import('@docusaurus/preset-classic').ThemeConfig} */ ({
// others....
algolia: {
appId: '3CRIMRK623',
apiKey: 'ae4f57f208e3c7749017e09582f0b8a4', // search only (public) API key
indexName: 'xiaominfo',
contextualSearch: false,
debug: true
},
}),
效果如下:
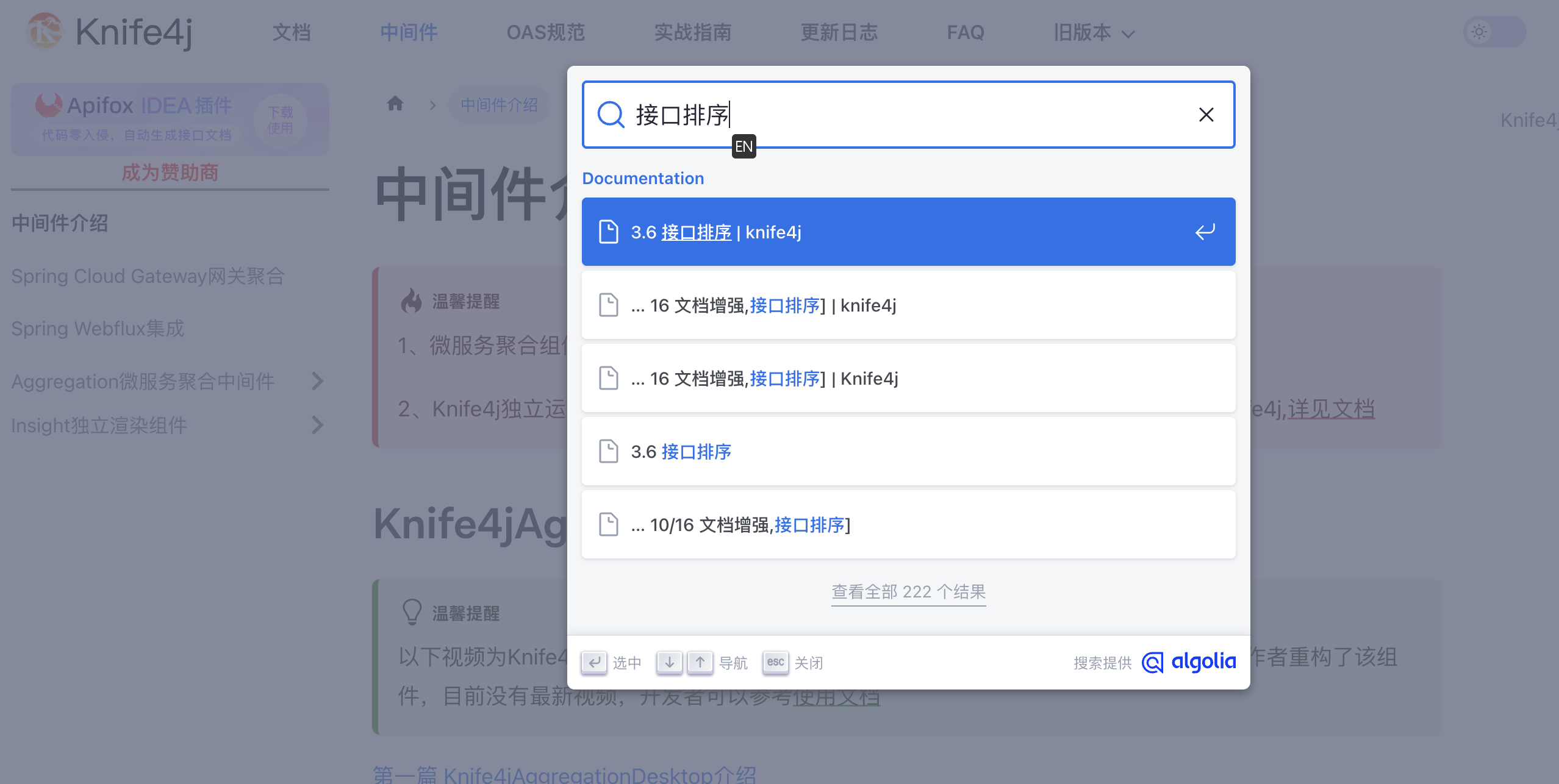
docusaurus的搜索插件可以查看文档:https://docusaurus.io/zh-CN/docs/next/search
 介绍的都是比较详细的,但是最值得注意的来了(这也是Knife4j在Algolia后台数据有了,就是死活搜索不出来)
介绍的都是比较详细的,但是最值得注意的来了(这也是Knife4j在Algolia后台数据有了,就是死活搜索不出来)
最坑的就是这个上下文搜索参数:contextualSearch
由于该参数在Docusaurus的插件中默认开启,导致他会和上下文约束面过滤器 (contextual facet filters) 会和 algolia.searchParameters.facetFilters 合并配合使用,增加了一些不必要的过滤器,最终就会搜索没有结果
如果你没有该需求或者场景,那么需要给他关闭,配置修改contextualSearch参数为false
我也是对比了步骤3中通过一个简单的html集成查看Algolia请求参数的差异才发现这个区别,为啥Knife4j明明数据有了,就是搜索不出来。。。。。累了。。。。
5.最后
目前Knife4j的官网文档终于开启了搜索功能,希望能够帮助到使用Knife4j的同学更好的检索文档。
如果有对Algolia不明白的,可以加Knife4j的微信讨论群(关注微信公众号点击菜单获取群二维码)与作者沟通交流。
